Aggregate variable
Function that computes aggregates on your ingested data
Definition
A variable is built with several components:
- Name: A label displayed in the builder to identify the variable
- Function: The method used to process and combine (aggregate) the selected data
- Field: The specific data field used to perform the computation (sum, average...)
- Optional Filter(s): List of criteria used to select a relevant subset of your data
List of supported functions and their descriptions:
| Function | Description | Default if no rows found |
|---|---|---|
| Average | Calculates the mean value of a set of numbers. | NULL |
| Count | Counts the total number of items. | 0 |
| Count distinct | Counts the number of unique items. | 0 |
| Max | Finds the highest value. | NULL |
| Min | Finds the lowest value. | NULL |
| Sum | Adds up all the values. | 0 |
Example
Suppose we want to check if the average payout transaction over the last 7 days exceeds €15,000. Here’s how we can achieve this:
- Select the Function: Choose the "Average" function to calculate the mean value of the payout transactions.
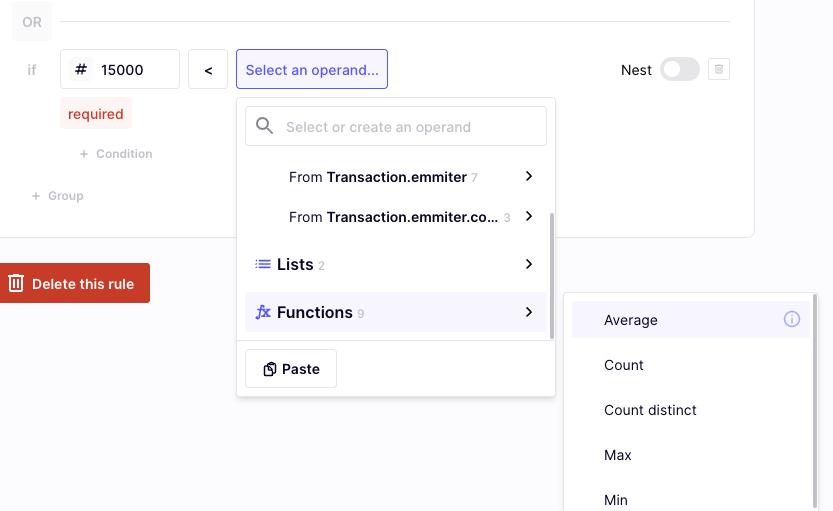
Select the average function in operand picker
- Choose a name for the variable: it does not impact how it's computed, but will help make your rule more readable in the builder
- Choose an aggregation function: the type of aggregation that you want to compute
- Choose an entity and field to aggregate on: Choose the target field on which you want to aggregate. You will be able to add filters on this table's field in the following step
- Add filters: Add the relevant filters that you want to filter on, on the target field table.
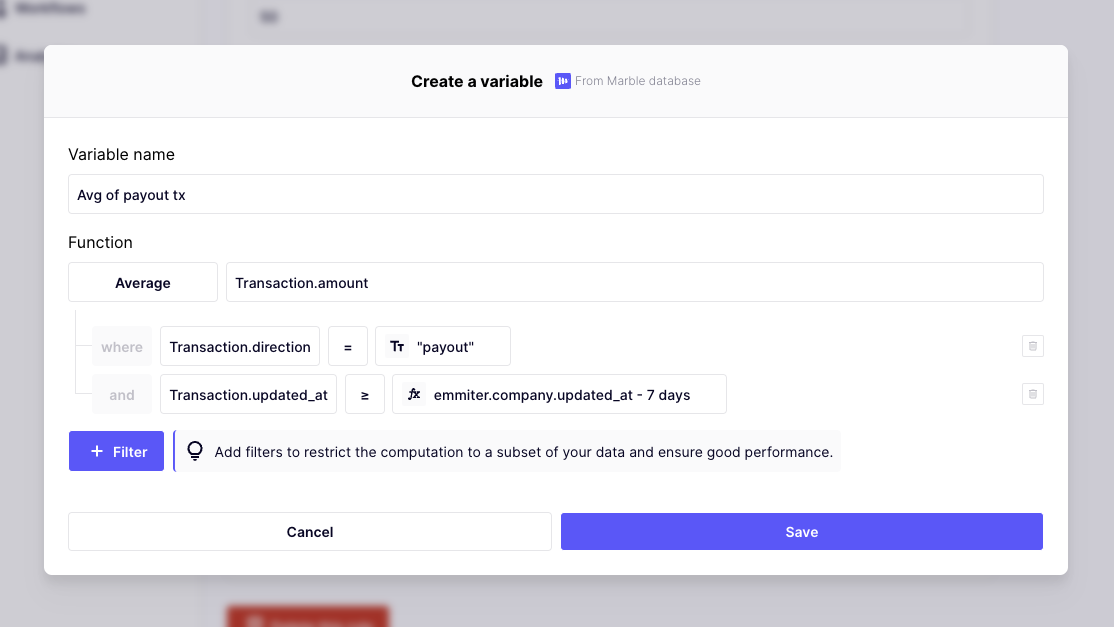
Average of last week's payout transactions
- Save and View: After saving, the variable will be displayed in the builder, showing the specified condition.
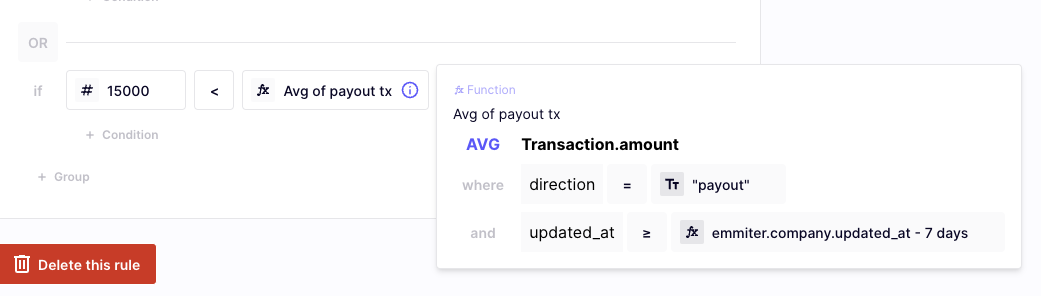
Filters
Available options
Filters work similarly to comparison operators in the formula, but with some limitations specific to how they are used.
They work in the context of a target table, that is to say the table (or data model entity) whose field we want to aggregate.
- The left-hand field must be a reference to a field from the target table, while the right-hand field can take any value allowed in the builder (except nested aggregate variables)
- Most of the operators from the ruile builder are available in aggregates filters. You can still use operators like
>,=,<etc, as well as theis in listandis not in listoperators.- Numeric operators:
>,=,<etc - List operators:
is in listandis not in list - Empty checks:
is empyandis not empty - Text operators:
starts with,ends withandis similar toFuzzy matching operatorThe
is similar tooperator works the same way as the String similarity function in the rule builder. For a detailed walkthrough, see String similarity.
- Numeric operators:
Necessity of using filters
It is almost always important to specify a sufficient set of filters in the variable, so that the aggregation can be computed quickly. Marble will make sure to index the values as best as possible to ensure a quick computation, but an aggregate that averages over all values in the database is bound to be slow, and may lead to critically slow response times and/or timeouts.
See below an anti-pattern and an improvement on it.
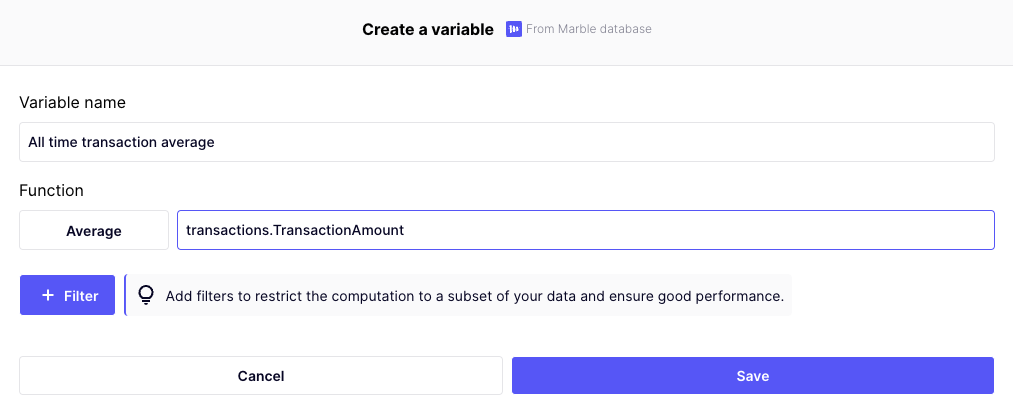
Anti-pattern: this aggregate will be too slow to compute. It is not specific to a customer, and not time-bounded.
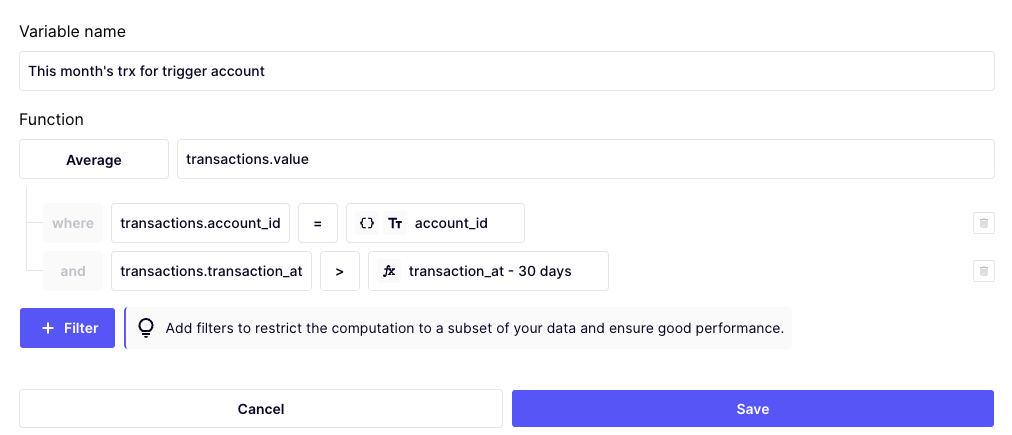
Possible improvement: filter by date and account_id
Example
Let’s say we’d like to check if the creditor name, indicated by the emitter of a transfer, matches at least one the aliases registered by our customer.
- Create an aggregate: create a count aggregate, that will count aliases' object IDs.
- Compare to creditor name: use the
similar tooperator to compare the aliases full name with the transaction creditor name. Here, we will prefer the « bag of words » (see String similarity) comparison with a high sensitivity - Set the hit condition: here, we want the rule to be triggered if no matches are found, so we select the
=operator with value 0.
Here is a video walkthrough to help you build this type of rules:
Updated 3 months ago