Ingesting data
How and why to ingest data. Interfaces and formats.
When to ingest data
When making a decision with the Marble decision engin, you can rely on 3 types of data:
- live data from the payload (or trigger) object
- data stored in lists
- data ingested, out of which
- field values from parent tables (see links)
- aggregates computed on any table in the data model (with filters derived from the payload object)
You will almost always need to ingest historical data to leverage on decisions, as this is the most "powerful" and complete source of data available.
The value of Marble is that, once your data has been ingested (or rather, is being continually ingested), the tool abstracts away the tedious work of defining aggregates in your code, creating indexes, doing real time calculations...
How it works
Versioning
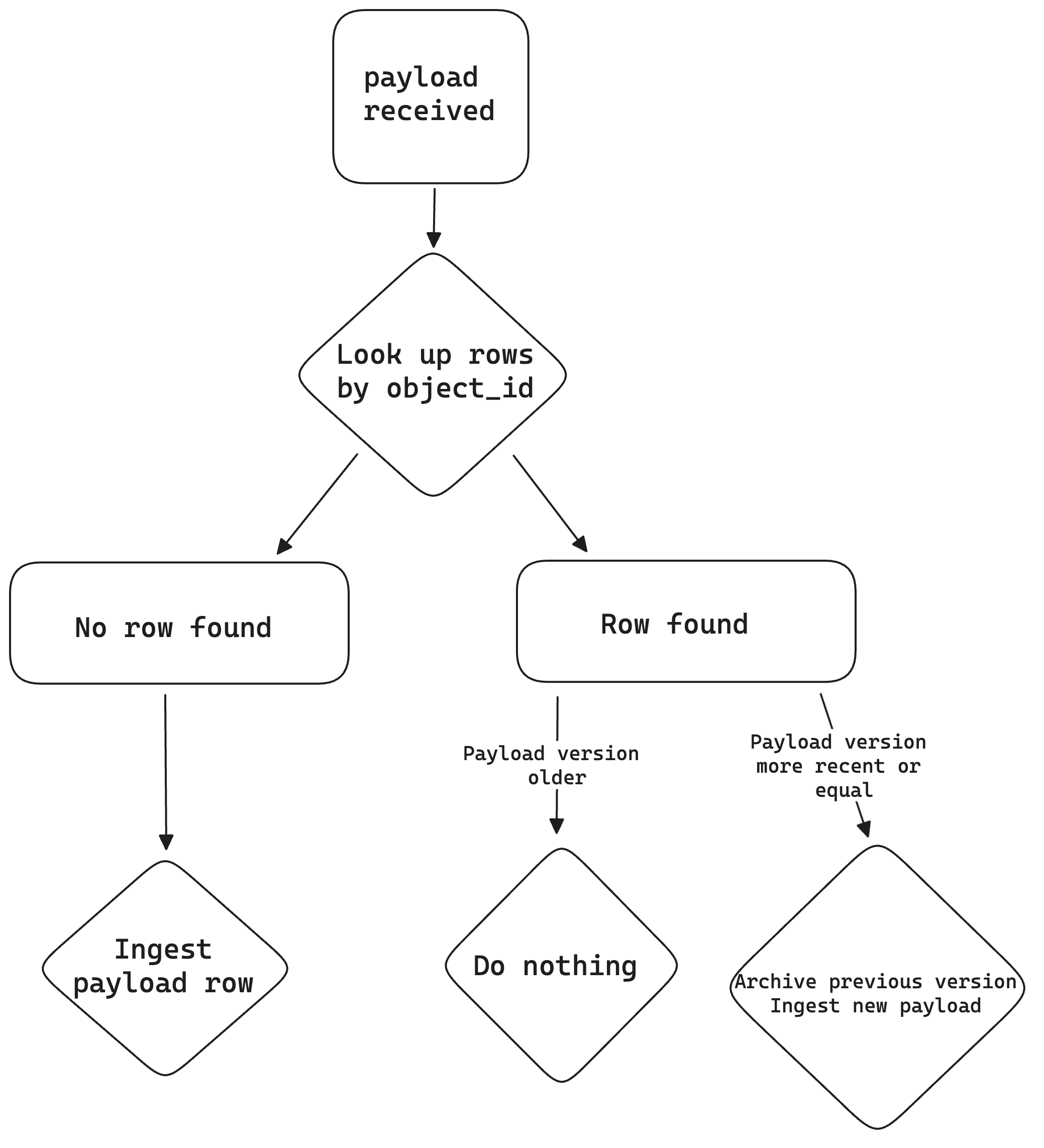
Marble keeps a history of the successive versions of an ingested object, reconciled by the values of object_id and updated_at.
When you send a payload for an object, we do the following:
- Search any existing ingested rows matching the input
object_id - If no row exists, insert a row
- If a row exists, compare its
updated_attimestamp to the payload timestamp: if the payload timestamp is greater or equal to the existing row timestamp, ingest the new row and move the old one to archive - else do nothing
This allows Marble to keep a full audit trace for all past decisions.
Data storage
By default, the ingested data is stored in a database schema specific to the organization in the Marble database. If you are using the open-source engine, that is the database your used to run Marble.
If you are using the hosted Marble SaaS offering, this could be either a common database instance common to several customers, or a dedicated DB instance for better performance guarantees (contact us: [email protected]!).
Input validation
When ingesting data, we perform input validation based on the declared data model.
In particular, we verify:
- presence of required fields for the selected table
- type validation according to the declared field type (string, boolean, number, timestamp)
- where applicable (i.e. for timestamps), format validation for parsing
Timestamp formatWe expect RFC3339 format timestamps. Below are some examples of valid timestamps:
- 2024-05-29T15:21:09Z
- 2024-05-29T15:21:09+01:00
- 2024-05-29T15:21:09.9283+00:00
- 2024-05-29T15:21:09
- 2024-05-29 15:21:09
Anything that deviates from this format is probably going to be rejected - though if in doubt, test it or reach out to us.
If the timezone information (
Zfor UTC or an offset from UTC) is not provided (like in the last two examples), the timestamp will be assumed to represent a moment in time in UTC (+00:00).
Additional properties in the payload are ignored by API and rejected in batch CSVs.
Chart
Ingestion workflow
Ingestion methods
By API
You can find our API documentation for ingestion here.
You will also find an automatically generated Openapi spec corresponding to your specific data model in the Marble API section of the console.
Ingest data by calling https://api.checkmarble.com/v1/ingest/{table_name}. The data ingestion API is expected to be used with server to server credentials, and as such expects an API key that can be generated in the Marble console.
Production useIngestion by API is the preferred method of data ingestion. It will allow you to have the freshest data available for you decisions at any given time.
By batch (CSV files)
For the purpose of easier testing of the tool, and easiest ingestion of occasional data (any data that should be ingested but changes only rarely), we give access to a batch ingestion interface, accessible through the data model page.

Entry point for data upload
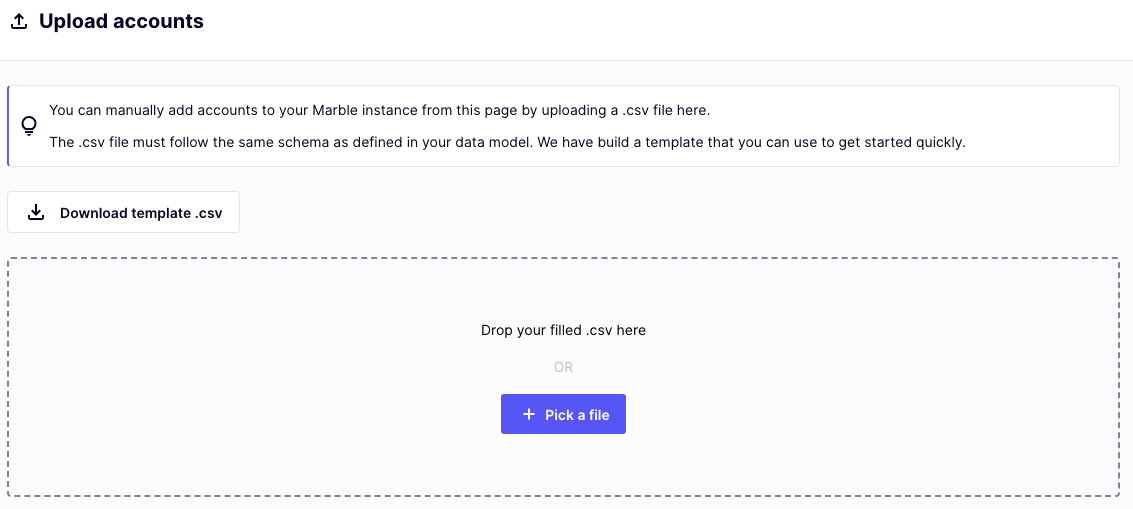
The data upload page
The page allows you to download a template .csv file, that you may complete with your data. In particular, the CSV should be coma-separated, and contain all required fields for the table.
The order of fields in the header row does not matter, as long as the values are ordered consistently.
When you drop a file on the upload page, we validate the rows against your data model as they are being sent, and notify you of any bad rows. If the validation is successful, the actual ingestion then happens asynchronously (but shortly after the validation).
Payload validationIf any object within a batch ingestion is rejected, the entire payload will be rejected. You must resolve the issue(s) with the problematic object(s) and retry the ingestion with a corrected payload.
We impose a 1 min timeout on the upload of the file. If you plan to send many rows (especially if you have many columns to send), this may limit the size of files you can send by this method.
Note that in batch ingestion from CSV, we will accept missing values from string fields as the empty string, except for the object_id which must take a non-empty value.
Initial data loadYou are likely to want to do an initial data load of historical data when you start operating Marble (assuming further ingestion happens in real time by API). The 1 min timeout is sure to be a bottleneck when doing this. We can assist you manually in this usecase, by bypassing an upload from the console.